
大数据这个词已经火了好几年,我们所听闻的“超市中啤酒和纸尿裤摆放在一起”这样的例子其实就是大数据的基础性应用。这些一般是根据简单的数据采集和经验判断得出的结果,但真正的大数据挖掘靠的是复杂的数据建模,以及模型的叠加和阶段性更新才能获得用户期待的效果。
京东(JD.com)一直是大数据应用的践行者。2014年的京东技术嘉年华上,京东就曾经分享过如何应用大数据做到“智慧零售”,而最近,京东对其PC页面和手机APP等进行了改版,“今日推荐”和“猜你喜欢”这两个板块不再千篇一律,而是实现了“千人千面”。
“千人千面”意味着每个人在PC或移动端打开京东网页时,看到的是完全不同的一组推荐产品,推荐给你的可能是洗发水和按摩椅,推荐给我的可能是手机壳和一本儿童剪纸书。而且,京东表示,这种推荐的结果是,用户购物决策的质量和效率提升了,忠诚度提高了,移动端个性化推荐订单贡献已经达到10%,可谓是双方都满意,皆大欢喜。
那么这样的“大数据服务”是如何实现的呢?京东推荐搜索部总监刘尚堃近日与记者分享了“千人千面”背后的大数据故事。
京东(JD.com)把这种以推荐方式吸引用户再次回到京东采购商品叫“召回”。召回是基于之前的数据采集进行分析的。那么也就是需要多种不同的“召回模型”。
根据刘尚堃的介绍,目前京东正在采用的召回模型有三种。第一种是基于行为的召回模型,这个理解起来比较简单。如,我刚刚在京东上购买了一部Kindle,那么京东会推荐我kindle周边产品,比如一个kindle的保护套,这种是与用户的购买行为相关。又如我再京东上浏览了一本金融书籍,京东会根据我的浏览记录给我推荐相近的股票书籍。总之,这种推荐是比较直接的,而且刘尚堃也提到,他们最近还尝试将用户刚刚浏览过的商品直接推荐给用户,这种“直白”的推荐是他们之前不屑于做的,但居然也起到了意想不到的好效果。
第二种召回模型是基于用户的偏好进行推荐,也就是基于数据,对用户、商品及店铺进行画像。下图中,我们可以清楚的看到画像的元素。京东后台会对这些画像进行配对,推荐合适的商品。比如一位男士,在京东上多次采购和浏览高档品牌白色T恤,那么他的画像就被定位为“男、高收入、T恤、白色、……”,当有相应高档品牌上新白色T恤时,京东会自动推荐给这位男士。
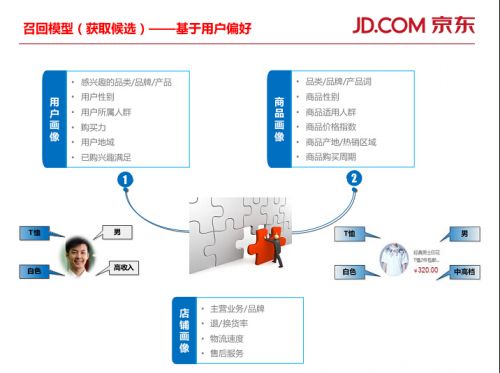
京东用户可以通过京东的PC端、移动App以及微信和手Q进行采购。一般而言,办公环境下用户更喜欢在PC上购物;移动、家居环境下用户越来越喜欢蜷在沙发里在京东主APP和微信手Q上购物。当然,也可以在PC端看仔细,加入购物车,之后有空在移动端确认付款。根据不同屏幕展示限制,京东也会推荐相应地产品。
第三种召回模型是基于地域。不同城市的消费水平当然不同,同一个城市的不同区域也有着不同的消费习惯。北京酒吧街三里屯附近的采购集中在了扑克、饮料、矿泉水等娱乐类商品,而东北五环的庞各庄小区的采购则集中在了晾衣架、棉袜、鼠标、充电宝等生活类商品,对于来自这两类不同局域的用户,京东推荐的品类也会有所侧重。
当然,这三种模型属于宏观模型,以下还有很多子模型,如在线相关、在线相似、离线相关、离线相似,以及近期比较热销的品牌和品类等。这些子模型都会进入到模型库当中,基于一些算法进行模型效率分析,也就是看单位展示量中哪种模型效率最高。同时,京东会根据测试结果进行模型权重的调整,并不断进行新的尝试——比如把用户直接放在购物车中的商品再次推荐给用户,结果在原有算法基础上又有了5%到10%的提升。后来刘尚堃的团队又将这些召回模型借助新的算法进行排序,模型效率再度提升了20%。
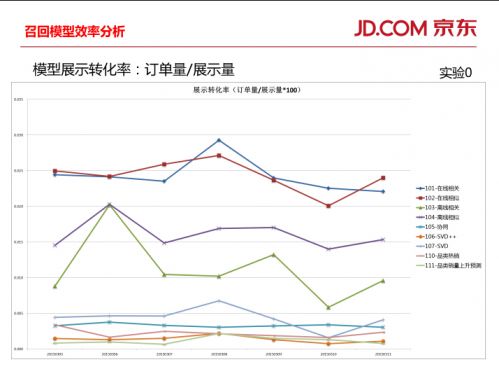
刘尚堃也表示京东也在探寻如何向用户展示一些可能会感兴趣但不会马上购买的品类,如手机、情侣睡衣、冰箱、笔记本、手表、平板电视等等,因为这些商品使用时间长,采购前的思考周期也比较长。他们正在尝试定制某种展示机制,希望得到相应的效率提升。
目前,京东建构模型所采用的数据多数来源于京东采购记录,未来也会考虑采用社交媒体的数据,进行辅助。刘尚堃说,他们也在积极尝试新的算法和排序模型,并且就架构本身来说,能够支持算法的高速迭代,京东平均每周会有7个新的算法实验上线。在未来,搜索团队基于大数据召回率预计还有50%的提升。
通过“千人千面”的商品推荐,大数据为京东带来了实实在在的利润。相信也会有更多的大数据故事,酝酿在各个行业和企业,为企业带来生机。



