
今天很高兴能和大家一起聊聊中国的数据分析与人工智能。AI在全球都很热,但在中国,它的发展路径和关注焦点确实有其独特性。在我和Gartner团队的日常研究与合作中,我们能清晰地感受到这一点。因此,我和团队特意筛选了一些与中国市场紧密相关或备受国内业界关注的技术,为大家绘制了这份具有“中国特色”的技术成熟度曲线。
技术成熟度曲线,是Gartner最核心的分析工具之一。它的终极目的,其实是来纠正我们一个常见的认知偏差:人们总是会高估一项技术的短期影响力,却又低估它的长期价值。这就像投资市场里的情绪波动,非常普遍。
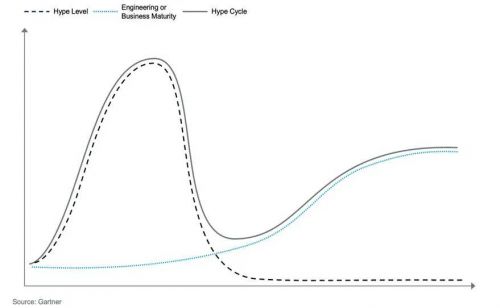
2025年中国数据、分析和人工智能技术成熟度曲线
大家看上面这张图,这条典型的曲线,其实是由两条虚线叠加而成的:
- 较粗的虚线,代表的是“炒作声量”:它通常会急速冲上一个顶峰,然后逐渐冷却。比如三年前的ChatGPT和大语言模型,去年的生成式AI,以及眼下最热的AI智能体(AI Agent),都经历了或正在经历这个过程。
- 浅蓝色的线,代表的是“技术成熟度”:它涵盖了技术、工程和业务应用的成熟程度,爬升得比较缓慢但持续。
- 这两条线一结合,就形成了我们看到的这条“过山车”曲线。当一个技术(比如现在的AI智能体)处在曲线顶端的红点时,就意味着它备受瞩目,但成熟度还很低,形成了典型的“泡沫期”。
在我的解读里,我们习惯给这个周期起几个更形象的名字:
- 愚昧之巅:就像去年国内的“百模大战”,几百个模型涌现,投资火热,期望值被拉满,厂商众多,大家都非常兴奋。
- 绝望之谷:热度退去,厂商开始洗牌,出现并购、价格战,大家回归理性,觉得这技术好像也没那么神奇。
- 开悟之坡:技术开始真正沉淀下来,产生实际业务价值,市场上出现了成熟、稳定、易用的产品或解决方案。坦白说,目前很多热门技术,还远未到达这个阶段。
接下来,结合我的观察,重点为大家分享几类在国内备受关注的技术趋势。
首先是大语言模型。从我接触的Gartner客户和调研数据来看,它的热度确实在从顶峰回落。从ChatGPT横空出世,到“百模大战”,再到现在大家越来越冷静,这是一个必然的过程。我们预计,这种理性的回调还会持续。
那么,我们该如何看待大语言模型的现状呢?GPT-5的发布就是一个很好的观察点。之前业界对它的期待非常高,甚至有声音说它将接近AGI。但实际发布后,大家发现它带来的震撼不如预期。这表明,大语言模型的能力在经历早期飞跃后,目前可能正触及一个平台期。从国外专业的模型评测网站数据也能看到,OpenAI虽然依然领先,但优势不再那么悬殊,整个市场进入了一种“青蛙跳”式的混战格局,你追我赶,但差距微小。
在国内,DeepSeek、通义千问、智谱GLM、Kimi等模型也呈现出类似态势。对于大多数企业应用而言,头部模型之间的性能差异已经不那么关键。正因为现实发展与早期的高预期产生了落差,市场才会回归冷静。同时,我们也观察到一个新趋势:模型正在向精细化、小型化发展,Gartner已经开始用“小语言模型”来定义这一新兴趋势。
第二个是AI智能体。这是当前当之无愧的“顶流”。它为什么潜力巨大?根据Gartner定义,一个真正的AI智能体需要完成三个核心动作:感知环境、自主决策、执行行动,并且能在这个过程中通过反馈持续学习,形成一个闭环。
举个例子,如果一个制造企业的供应链由AI智能体管理,它就能7x24小时不停地去优化和调整,即使遇到突发问题,也能从中学习经验,这个能力是非常强大的。但理想很丰满,现实很骨感。为什么说AI智能体正处于“愚昧之巅”?因为目前市场上绝大多数标榜为“AIAgent”的应用,甚至算不上真正的智能体。我们观察到了一种“Agent Washing”现象——就像以前的“Green Washing”一样——很多厂商只是把原来的聊天机器人改个名字,就包装成了AI智能体。
在我看来,AI智能体的进化路径是:从聊天机器人,到能完成特定任务的智能助手,再到能应对复杂目标的自主智能体。目前,我们才刚刚踏入这个领域。虽然市场上有一些不错的探索,但名不副实的居多。不过,我依然长期看好它的未来。
这里需要澄清一个概念:我们这里特指的是“基于大语言模型的智能体”。智能体这个概念本身在AI领域历史悠久,像AlphaGo、推荐系统都是早期的智能体。而大语言模型的突破,在于它让智能体有了更强的通用理解和推理潜力,能把我们生活中的各种元素串联起来。当然,未来的智能体未必只依赖大语言模型,它很可能是一种混合架构。
如果给当前基于大语言的AI智能体打个分(1.0版本),它的语言理解能力可能达到4.5星,行动能力在良好提示下也能到4星,但它的复杂决策能力,尤其是在需要深谙企业业务背景的场景下,可能只有3星。所以企业在当前阶段应用时需要非常谨慎。可以打个比方:大语言模型是发动机,而AI智能体是整车。发动机可以换,但整车的设计和制造是另一回事。
第三,我们来谈谈“AI就绪数据”。 这是我特别想向企业客户强调的一点。无论是智能体还是大模型,都逃不过机器学习那句老话:“垃圾进,垃圾出”。对于企业级应用,你不可能只靠模型固有的知识,必须给它输入企业自身的知识库、历史数据等上下文。如果这些数据质量不行,结果必然不理想。
“AI就绪数据”需要满足几个维度:
- 高质量与可访问:数据本身要准确,架构要清晰,不同系统间的数据要能关联打通。
- 良好的治理:要有数据标准、合规性保障和明确的责任主体。
- 持续改进:数据是流动的,必须建立起持续优化数据质量的机制。
现在业界常说的“上下文工程”,其基石就是高质量的“AI就绪数据”。越来越多的企业意识到,想用好AI,先管好数据。
第四点是AI治理。 我们的调研发现,2023到2024年,国内生成式AI在生产系统中的实际应用比例还不高,大约在6%-8%。但我们预测,到2025年,这个比例会飙升至40%以上。当AI真正深度融入业务,影响企业收入和品牌时,治理就变得至关重要。
比如,一个客服AI如果对客户出言不逊,直接就是品牌危机。而随着未来能自主行动并代做决策的AI智能体普及,治理的复杂性会指数级上升。
在我的分析框架里,AI治理主要围绕三个主题展开:
- 战略与政策:企业必须明确AI的使用规则、伦理边界和控制方法。
- 治理与运营模式:要有专门的团队、清晰的职责和顺畅的协作流程。
- 监督系统:需要借助技术手段对AI进行监控和约束,比如进行全面测试、设置“安全护栏”,甚至用一个大模型去监督另一个大模型的行为。
这就好比飞机的自动巡航系统,既要有先进的技术保障,也离不开飞行员的监督和最终的操控。
第五分享的是“复合AI”,这也是我个人非常推崇的一个方向。它的核心理念是:大语言模型很强大,但它不是AI的全部。未来的AI系统,尤其是强大的AI智能体,必将是一个融合了多种AI技术的“混合体”。
比如:大语言模型擅长聊天、翻译和总结。图技术擅长处理实体关系,比如知识图谱和路径规划。仿真技术在模拟复杂物理场景方面无可替代。优化求解器在做资源调配和排产计划时,比大模型可靠得多。机器学习则长于基于历史数据的预测。把这些技术像乐高积木一样组合起来,取长补短,构建的混合AI系统,其能力和可靠性会远远超过单一依赖大模型的系统。
最后,总结一下我今天的分享:回过头再看这张技术成熟度曲线,我的判断是:大语言模型正在滑向“绝望之谷”,趋于理性。AI智能体正处于“愚昧之巅”,需要警惕泡沫。而AI就绪数据、AI治理和复合AI,正受到越来越多务实企业的关注,它们是为数年后真正收获AI价值所必须打下的基础。希望我的这些分析和观察,能帮助大家在AI的浪潮中看得更清,走得更稳。谢谢大家!



